13章 - DynamoDB (後半)
前回の続き↓から行う.
urhayataro.hatenablog.com
データベースから特定の要素の取り出し
ここではデータベース上で条件を指定し,その条件にあったデータの取り出しをおこなう.
ディレクトリにあるdata.jsonを利用してBatch writeにより複数のデータを一度に書き込む.
import json
with open("data.json", "r") as f:
data = json.load(f)
with table.batch_writer() as batch:
for d in data:
batch.put_item(Item=d)
続いてデータの検索を行う.データの検索にはScanとQueryがある.
まず,Scanについて,これはデータベースの全てのデータを見て,対象のデータを検索する.
使い時は,partition keyやGlobal secondary indexが無いときに使用する.
次に,Queryについて,これは対象となるpartition keyを探し,データを検索する.
Scanと違い,全てのデータは見ないため,partition keyがあればこちらのほうが効率的と言える.
Queryによるデータの検索
では,partition keyを使ってQueryを実行する.
from boto3.dynamodb.conditions import Key, Attr
resp = table.query(
KeyConditionExpression=Key('username').eq('namihei_isono')
)
pprint(resp.get("Items"))これは,KeyConditionExpressionに検索の条件を渡し,partition keyであるusernameがnamihei_isonoの値を検索している.
実行結果は以下のようになる.

次に,上の実行結果のdoseについて見てほしい.namihei_isonoで検索したため,2回ワクチンを受けたなら2回分出力されている.
では,1回目のみ表示したい場合はどうすればいいか.これは&をつける(論理積をとる)ことで条件を追加できる.また,|をつける(論理和をとる)こともできる.
usernameがnamihei_isonoで,doseが1の場合を検索するようにしたのが以下のもの.
resp = table.query(
KeyConditionExpression=Key("username").eq("namihei_isono") & Key('dose').eq(1)
)
pprint(resp.get("Items"))出力結果は次のようになり,1回目のみ出力されている.

では,ageの属性を使ってQueryを実行する.これも先程と同様にKeyConditionExpressionでkeyでどの要素かを指定し,eqでどの値かを検索する.
今回は11歳のデータを検索する.
resp = table.query(
IndexName="ItemsByAge",
KeyConditionExpression=Key('age').eq(11),
)
pprint(resp.get("Items"))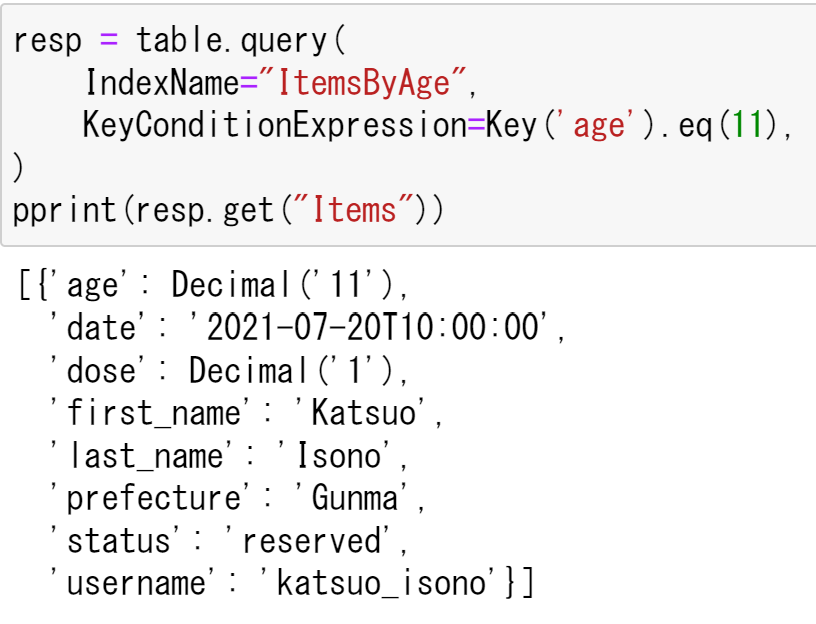
同様にprefectureがTokyoのデータを検索する.
resp = table.query(
IndexName="ItemsByPrefecture",
KeyConditionExpression=Key('prefecture').eq("Tokyo"),
)
pprint(resp.get("Items"))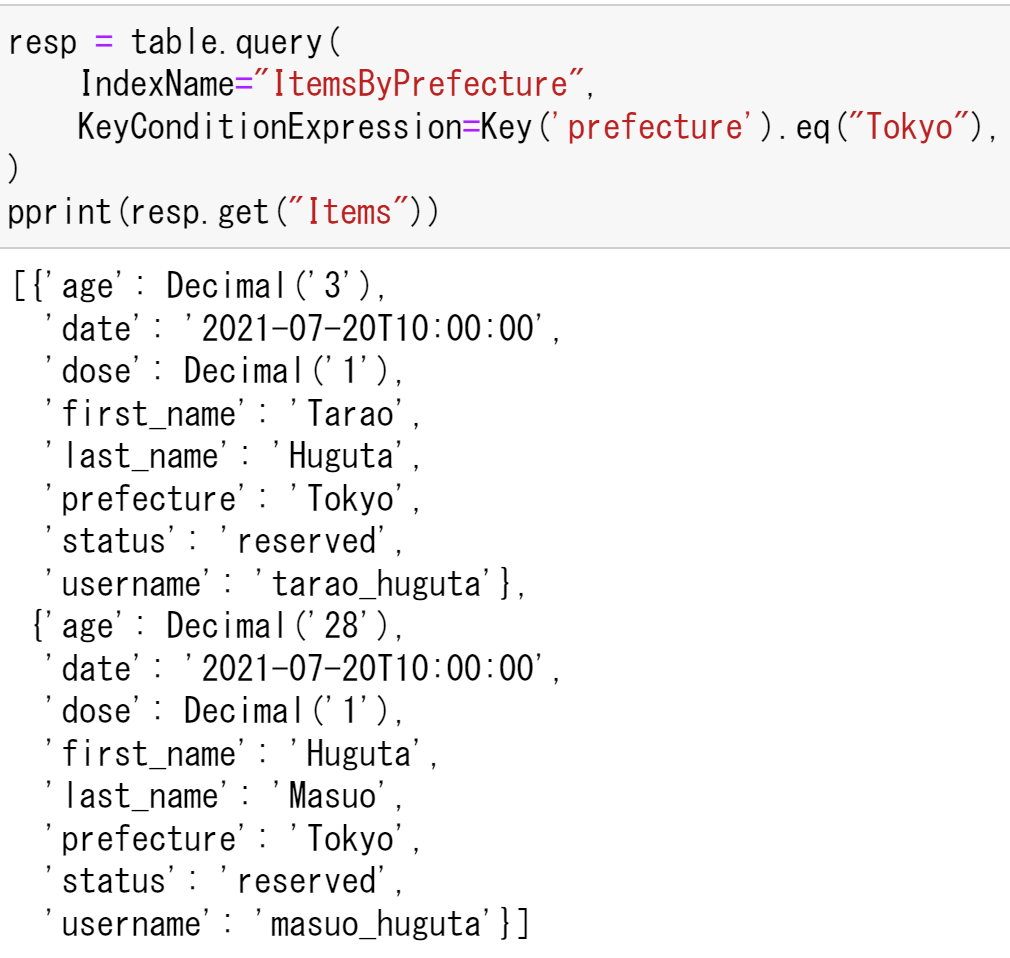
ここまでで,Queryは以下のようにすると使えることがわかった.
resp = table.query(
IndexName="ItemsByPrefecture",
KeyConditionExpression=Key('検索する属性').eq("検索する内容"),
)
pprint(resp.get("Items"))
Scanによるデータの検索
全てのデータを検索
はじめに,条件を指定せず全てのデータベースの要素を取ってくる.
resp = table.scan()
items = resp.get("Items")
print("Number of items", len(items))すると以下の出力が得られる.

ただ,ScanもQueryも1MB以上の範囲を検索できない.それ以上検索したければ,前回検索した続きから検索を続ける必要がある.以下のようにすれば良い.
resp = table.scan()
items = resp.get("Items")
while resp.get("LastEvaluatedKey"):
resp = table.scan(EsclusiveStartKey=r[:"LastEvalutedKey"])
items.extend(resp["Items"])
print("Number of items", len(items))Scan()から返されるディクショナリにLastEvakutedKeyがある.これが空ならデータベース内が全てScanし終えたことを意味する.
Scan()を続きから実行する場合には,ExclusiveStartKeyに前回呼んだ最後のprimary keyを渡す.このコードでは,LastEvakutedKeyが空になるまでScan()を繰り返すようにしている.
実行結果は以下のようになった.

条件をつけて検索
Scanの場合は,Filter Expressionに特定の条件を記述する方法で検索することができる.
例として,ageが27以下の要素を検索する.
resp = table.scan(
FilterExpression=Attr('age').lt(27)
)
print("Number of items", len(resp.get("Items")))
同様に,dateが2021-07-25の要素を検索する.
resp = table.scan(
FilterExpression=Attr('date').begins_with("2021-07-25"),
)
pprint(resp.get("Items"))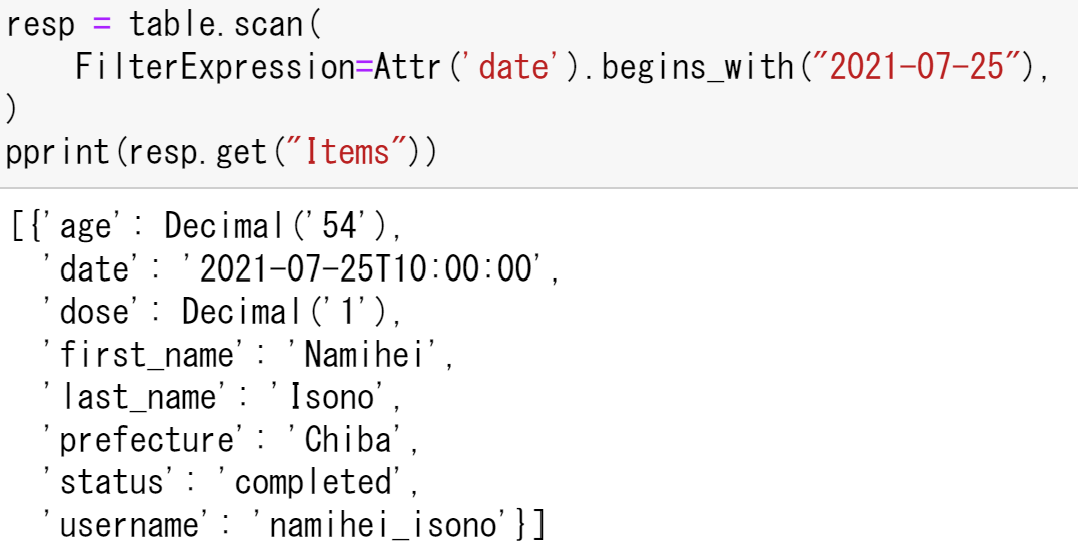
これで,2行目のFilterExpression=以下で条件を定めれば,検索をかけられることがわかった.
Scanで検索するときに一部の属性を取り出すという便利な検索の方法がある.
その方法は,ProjectExpressionを使用することで,指定した属性のみを表示することができる.
今までは,条件に合ったデータを持ったもののデータを全て表示していたが,例えば,first_nameとprefectureのみを取り出すこともできる.
resp = table.scan(
ProjectionExpression="first_name, prefecture"
)
print(resp.get("Items"))
これで名前と住所のみ取り出せていることがわかる.
バックアップを取る
バックアップの流れ
データベースを扱うときに必須であるバックアップの取り方について触れていく.
流れとしては,バックアップを取り,データベースを書き換え,復元する.元のデータベースになっていれば成功という感じだ.
バックアップの取得
バックアップはTable()ではサポートされていなので,client()を使って行う.
まず,DynamoDBのclient()オブジェクトを作る.
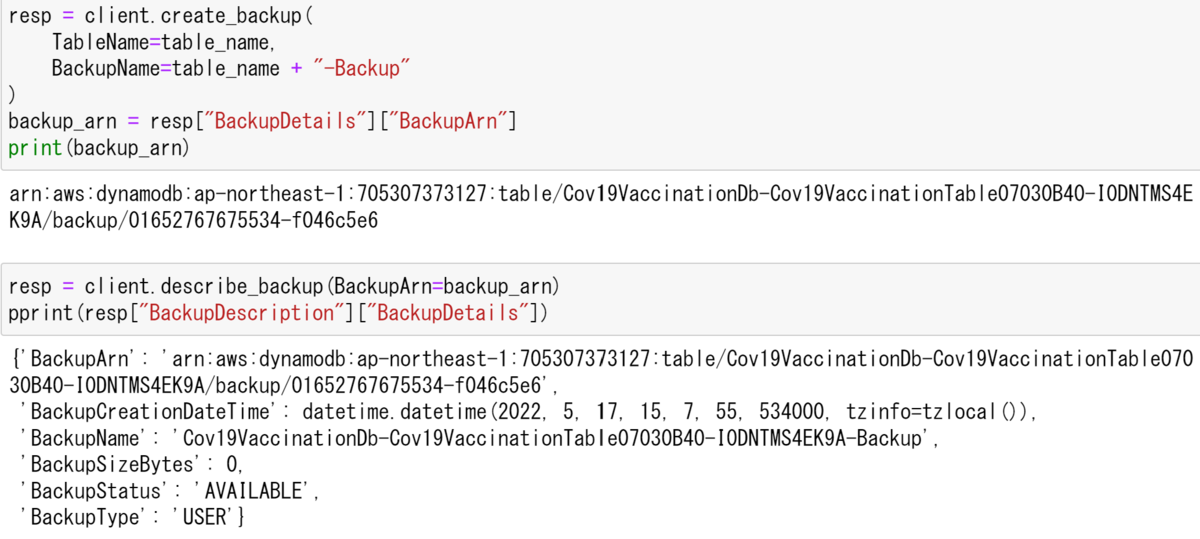
client = session.client("dynamodb")次に,バックアップを取るためのcreate_backup()を使って書いていく.これにバックアップを取るテーブル名と,バックアップの名前を指定する必要がある.これが2,3行目に該当する.また,BackupArnは,バックアップのIDとなっている.
resp = client.create_backup(
TableName=table_name,
BackupName=table_name + "-Backup"
)
backup_arn = resp["BackupDetails"]["BackupArn"]
print(backup_arn)続いてバックアップの情報を取得する.
resp = client.describe_backup(BackupArn=backup_arn) pprint(resp["BackupDescription"]["BackupDetails"])
以下のような出力が表示されるはずだ.
ここまでできれば,AWSの方でバックアップが取れているか確認する.
AWSからDynamoDB→テーブル→テーブル名→バックアップを確認する.
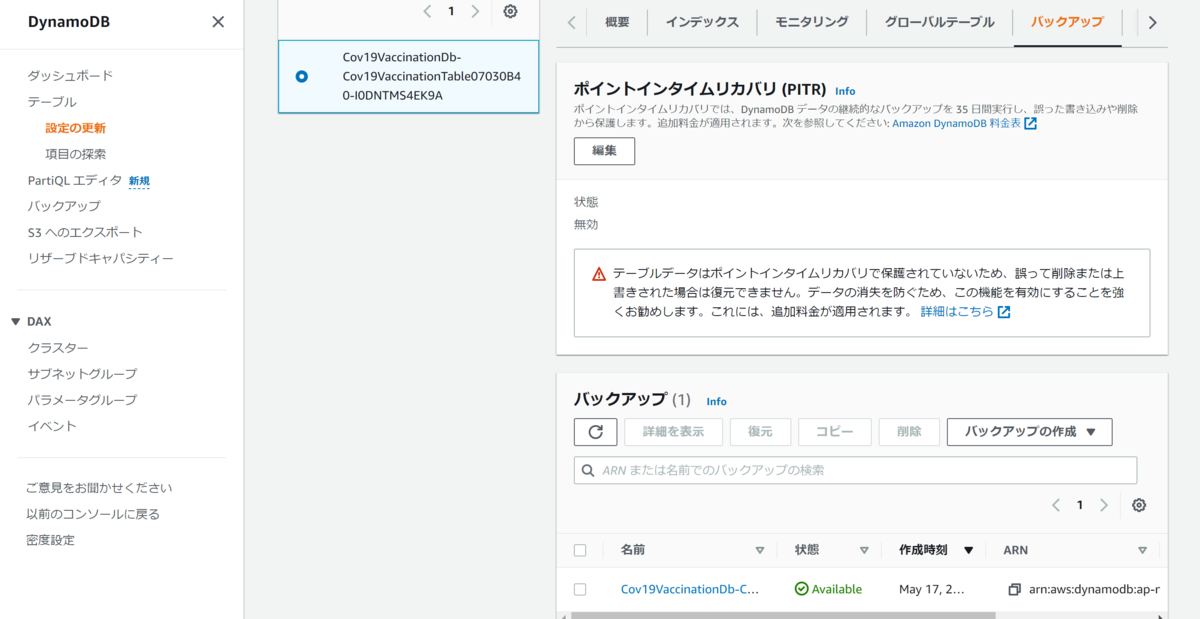
バックアップが1つあり,状態がAvailableとなっている.
これでバックアップが作成できたことがわかった.
データベースの書き換えと復元
まず,元のデータベースを書き換えてみる.書き換えるのは何でも良い.
前半のデータベースの更新を参考に書き換えていく.
urhayataro.hatenablog.com
resp = table.update_item(
Key={"username": "tarao_huguta", "dose": 1},
UpdateExpression="SET age = :val1",
ExpressionAttributeValues={
":val1": 4
}
)
resp = table.get_item(
Key={"username": "tarao_huguta", "dose": 1},
)
pprint(resp["Item"]["age"])すると値が書き換えられた.

書き換えが終われば復元してみる.
restored_table_name = table_name + "-restored"
resp = client.restore_table_from_backup(
TargetTableName=restored_table_name,
BackupArn=backup_arn,
)2行目の.restore_table_from_backup()でバックアップの復元を行っている.
また,1行目で復元後のテーブルの名前を指定し,3行目に渡している.
続いて,復元したテーブルの状態を確認する.確認は以下のように行う.
resp = client.describe_table(TableName=table_name + "-restored") pprint(resp["Table"]["TableStatus"])
describe_table()でテーブル名を指定し,そのテーブルの状態を表示させている.

復元直後はCREATINGとなり,しばらくするとACTIVATEになる.ACTIVATEにならないとデータベースの読み書きができない点に注意する.
復元が終われば,書き換えたところをもう一度読み取り,復元できているかの確認を行う.
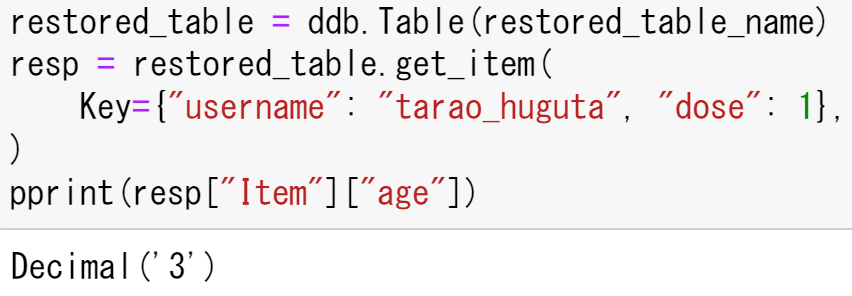
restored_table = ddb.Table(restored_table_name)
resp = restored_table.get_item(
Key={"username": "tarao_huguta", "dose": 1},
)
pprint(resp["Item"]["age"])出力は以下のようになり,4と書き換えたのが,3に復元できていることから,バックアップでの復元ができていることがわかる.
これでデータベースのバックアップ及び復元を終える.
最後に復元されたテーブルと,不要なバックアップのデータを削除しておく.
restored_table.delete() resp = client.delete_backup(BackupArn=backup_arn)
それからスタックも削除しておく
cdk destroy
まとめ
13章後半ではデータベースについて扱った.
データの読み書きバックアップと復元について触れ,データの更新のやり方や条件に該当するデータの読み取りについても行った.
バックアップについて,よく行う作業だとは思うのでcreate_backup()での作成は大切になる.
以上で13章DynamoDBを終える.