データベースの作成と確認
はじめに
前回の続き↓でmodelを扱っていく。
urhayataro.hatenablog.com
モデルとはデータベースのことで、今回作成しようとしている本棚アプリケーションでは、どこにどのような本があるのかをまとめておく為にデータベースを作成します。
今回やることは、モデルの作成と作成したモデルの確認までを行います。
モデルの作成
どのようなデータベースを作成するかというと、それぞれidと名前、番号を持ったデータを作成します。

では実際にbook/models.pyに以下の記述を行います。
from django.db import models # Create your models here. class SampleModel(models.Model): # 追加 title = models.CharField(max_length=100) # 追加 number = models.IntegerField() # 追加
クラス名は何でも良いですが、SampleModelとしています。
titleは、データを呼び出すときに使う名前であり、CharFieldはtitleの型を示しています。CharFieldとした場合引数は、文字列の最大長を表すmax_lengthを指定する必要があります。
また、numberのIntegerFieldは整数型を表しています。
それから、アプリケーションで作成したデータベースを後に作成する管理画面に表示させるためにadmin.pyを使って設定していきます。
bookproject/book/admin.pyに以下を記述します。
from django.contrib import admin from .models import SampleModel # 追加 # Register your models here. admin.site.register(SampleModel) # 追加
ここまでできれば、データベースに反映させます。反映させるには、2つのコマンドが必要になります。それがmakemigrationsとmigrateです。
前者は、models.pyに基いてデータベースの設計図を作成します。後者は設計図をもとにデータベースを作成します。2つに分けている理由は、データベースへの誤った操作を防ぐためです。makemigrationsコマンドで誤った操作に対して一度エラーを吐いてくれます。
ではmakemigrationsコマンドを使い、設計図の作成をしましょう。
python3 manage.py makemigrations
これでbookproject/book/に、0001_initial.pyが作成されます。
次に、makemigrationsコマンドで作成された、0001_initial.pyという設計図をもとにmigrateコマンドを使い、データベースの作成をします。
python3 manage.py migrate
これでデータベースの作成ができました。
作成したデータベースの確認
データベースの確認は、管理画面で確認します。管理画面に入るにはユーザーでないといけません。そのためまずは、ユーザーの作成をします。
ターミナルで以下を入力し、ログインのためのユーザー名とパスワードを登録します。
python3 manage.py createsuperuser` ユーザー名 パスワード パスワード(再)
その後、サーバーを立ち上げ、127.0.0.1:8000/admin/にアクセスします。そしてユーザー名とパスワードを入力します。
python3 manage.py runserver
ログインができれば以下のような画面が表示されます。
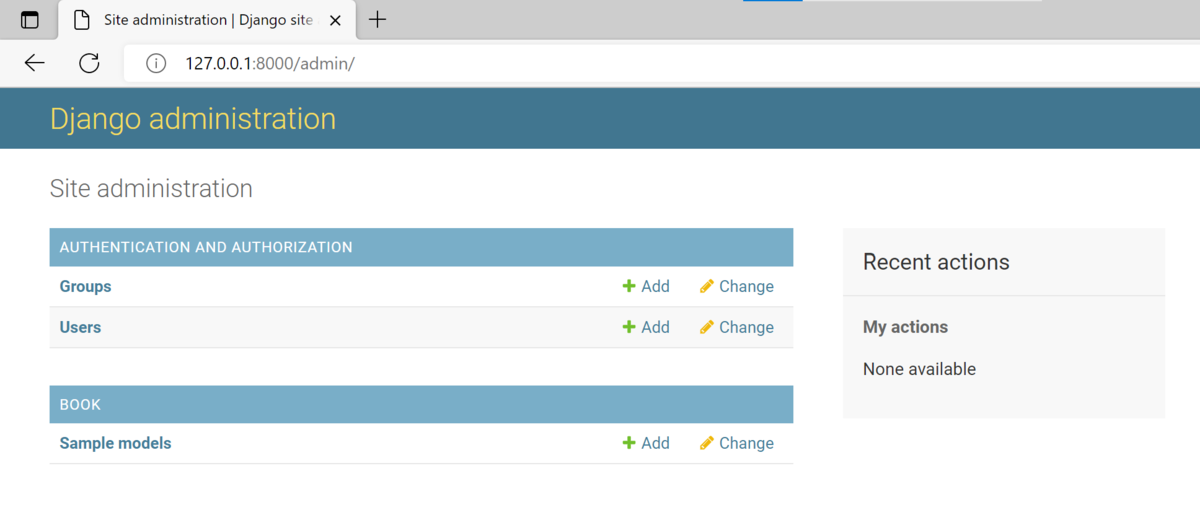
そして、Usersをクリックすれば、先程登録したユーザー名があるはずです。

また、Sample modelsの右にある+Addを押すと、titleとnumberが追加できます。ここでもデータをデータベースに保存することができます。
これでモデル(データベース)の作成ができました。
おわりに
今回はモデルを作成し、確認しました。models.pyとadmin.pyのファイルに記述し、makemigrationsとmigrateコマンドを使うとデータベースの作成ができることもわかりました。
vscodeでwslを使ってアプリケーションを作成する
はじめに
これからはvscodeとwsl2を接続してアプリケーションを作成していきます。
参考にした書籍はDjangoのコツとツボがゼッタイにわかる本です。
今回は
- vscodeとwsl2の接続(環境構築)
- 仮想環境の作成
- プロジェクト、アプリケーションの作成
を行います。
前提は、ubuntu20.04が入っていること、wsl2が使えること(wslはコントロールパネルのWindowsの機能で"Linux用Windowsサブシステム"と"仮想マシンプラットフォーム"に✓を入れていること)とします。Pythonは3.8.5を使っています。
vscodeとwsl2の接続
まず、vscodeを開き、拡張機能のところで "remote wsl" と入力します。そして、以下のものをインストールします。

インストールできたら、vscodeを再起動します。
再起動したら、左下のものを押し、クリック。


そして、ubuntu20.04を選択します。すると、新しいvscodeが立ち上がります。
左下が以下のようになれば成功です。

これからは、この状態でターミナルを開いてコマンドを打っていきます。
仮想環境の作成
はじめに以下のコマンドでパッケージをまとめてアップデートします。
sudo apt update sudo apt upgrade
その後、myvenvという名前の仮想環境を作成します。作成は以下のコマンドで行います。
python3 -m venv myvenv
venvは仮想環境を作成することを示したモジュールでmyvenvは仮想環境の名前です。
エラーによっては以下で解決出来るかも知れません。
sudo apt install python3.8-venv
作成した仮想環境を立ち上げるには、仮想環境を作ったディレクトリで以下を入力します。
source myvenv/bin/activate
sourceはファイルを実行するためのコマンドで、activateファイルを実行しています。
実行して、うまく仮想環境が立ち上がれば、以下の表記になるでしょう。
(myvenv)$
また、仮想環境の終了は
deactivate
仮想環境の削除は
rm -rf myvenv
ですることができます。
ここまでで、仮想環境の作成ができました。
プロジェクトとアプリケーションの作成
今後は、本を検索したり、詳細を確認、編集、削除などができる、本棚アプリケーションを作成していく予定です。そのため、ここではターミナルでのアプリケーションの作成までを行います。
まず適当なところで適当な名前のディレクトリを作成します。今回はproject3という名前にしました。
mkdir project3
作成したディレクトリに移動し、仮想環境を作成し、立ち上げます。
cd project3 python3 -m venv myvenv source myvenv/bin/activate
その後、Djangoのインストールを行います。
pip install django
次に、以前と同様にプロジェクトとアプリケーションの作成を行います。
urhayataro.hatenablog.com
django-admin startproject bookproject cd bookproject python3 manage.py startapp book
これで、"bookproject"というプロジェクトと、"book"というアプリケーションの作成ができました。
ここまででプロジェクトとアプリケーションの作成ができましたが、すこしだけ本棚アプリケーションの初期設定をしておきます。
ファイルへの書き込みを行うので、ターミナルに以下を入力します。このときのディレクトリはbookproject/とします。
code .
すると、新たなvscodeが立ち上がり、以下のようなエクスプローラーの画面が左に表示されます。

ここからファイルを開くことができるようになります。
ではbookproject/urls.pyに以下のコードを追加します。
from django.contrib import admin from django.urls import path, include # 追加 urlpatterns = [ path('admin/', admin.site.urls), path('', include('book.urls')), # 追加 ]
また、bookproject/settings.pyに以下のコードを追加します。
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'book.apps.BookConfig', # 追加
]
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [BASE_DIR / 'templates'], # 追加
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
これができれば、book/urls.pyを新規作成します。
作成はbookproject/bookに移動し、行います。
cd ~ /book/ touch urls.py
これで新規作成したurls.pyに以下を書き込みます。
urlpatterns = []
これで初期設定ができました。
おわりに
今回はvscodeとwsl2の接続、仮想環境の作成、利用したプロジェクトとアプリケーションの作成を行いました。
本棚アプリケーションの続きは今後行います。
urhayataro.hatenablog.com
Djangoを使ってweb上でHelloWorldを表示する
はじめに
今回やることは、前回の続きで作成したプロジェクト↓でweb上でHelloWorldを表示してみます。
urhayataro.hatenablog.com
記述をしていくファイルは、testproject/views.pyと、testproject/urls.pyです。
サーバーを立ち上げ、HelloWorldnoの表示を確認するところまでを行います。
vies.py
まず、testproject以下にviews.pyというファイルを新規作成します。vscodeかターミナルのどちらかで作ります。
作成したviews.pyに以下を記述していきます。
from django.http import HttpResponse def Helloworld(request): return HttpResponse('Hello World')
1行目のHttpResponseは、サーバーからブラウザ上に送るもので、ブラウザ上で何かを表示させるときに使います。
関数名はHelloworldを出力するので、そのままの名前にしています。
返り値は、ブラウザ上に表示させるもので、今回はHello Worldとしています。
urls.py
views.pyができれば、これを記述していきます。
from django.contrib import admin from django.urls import path from .views import Helloworld # 追加 urlpatterns = [ path('admin/', admin.site.urls), path('helloworld/', Helloworld), # 追加 ]
もともとあったコードに、3行目と下から2行目を加えました。
まず、3行目で同じくviews.pyで定義したHelloworld関数をインポートします。今回は、testproject直下にviews.pyを作成したのでこのような記述になり、testapp直下のviews.pyに記述した場合は、.viewsの部分がtestapp.viewsになります。プロジェクトとアプリケーションのどちらで作成しても同じ結果になります。
urlpatternsについては前回の記事で軽く触れましたが、urlがpath()の第一引数とマッチすれば第二引数を呼び出すというものなので、urlがhelloworld/なら、Helloworld関数を呼び出す形にしています。
次のコマンド実行後、127.0.0.1:8000/helloworld/にアクセスすると、HelloWorldが表示されるようにしました。
また、127.0.0.1:8000/でHelloWorldを表示させたければ、pathの第一引数を '' にすれば良いです。
サーバーの起動と表示の確認
サーバーを起動させるには、ターミナルで以下を実行します。
python manage.py runserver
エラーがなければ、127.0.0.1:8000/helloworld/にアクセスしてみます。

このように "HelloWorld" が表示されています。
サーバーの終了は、ターミナルでCtrl+cを押せば終了することができます。
もっときちんとしたwebサイトを表示させたければ、テンプレートというディレクトリを作成して、その中にhtmlファイルを作成する。そのhtmlファイルに記述して表示させることもできる。
おわりに
今回やったことは、前回の続きでweb上にHelloWorldを表示させてみました。
views.pyとurls.pyを記述すること、また、manage.pyのrunserverコマンドを使うことでブラウザ上で表示させることができました。
Djangoのインストールからアプリケーションの作成
Djangoのインストール
Pythonのバージョンは3.8.5を使用しています。
Djangoのインストールはコマンドプロンプトで
pip install django==バージョン
==バージョンは入力しなくてもok
自分のではDjango4.0.5が入りました。
これだけでインストールは完了した。インストールの確認は
python -m django --version
正しく入っていれば、どのバージョンが入ったか表示される。
プロジェクトとアプリケーションの作成
今回は、テストのプロジェクトを作成していきます。
開発にはvscodeを利用します。
vscodeでターミナルを開き、プロジェクトを作るディレクトリに移動。移動した場所にプロジェクトの作成を行う。ターミナルは、WSLを使用しています。
django-admin startproject testproject
今回、プロジェクト名をtestprojectとしましたが、ここは好きな名前を入れても構いません。
次に、アプリケーションの作成をします。アプリケーションの新規作成はmanage.pyがあるディレクトリで行います。先程プロジェクトの作成のときにmanage.pyはできたはずなので、ディレクトリに移動。
cd testproject
その後以下を入力してアプリケーションを新規作成する。
python manage.py startapp testapp
今回、アプリケーション名をtestappとしましたが、ここは好きな名前を入れても構いません。
ここまでできれば、vscodeでフォルダを開いてみる。ディレクトリとファイルの構成は
プロジェクト名
|_プロジェクト名
|_アプリケーション名
|_manage.py
のようになっている。

ここまででプロジェクトとアプリケーションの作成ができました。
プロジェクトとアプリケーションの構成のイメージは以下のものです。
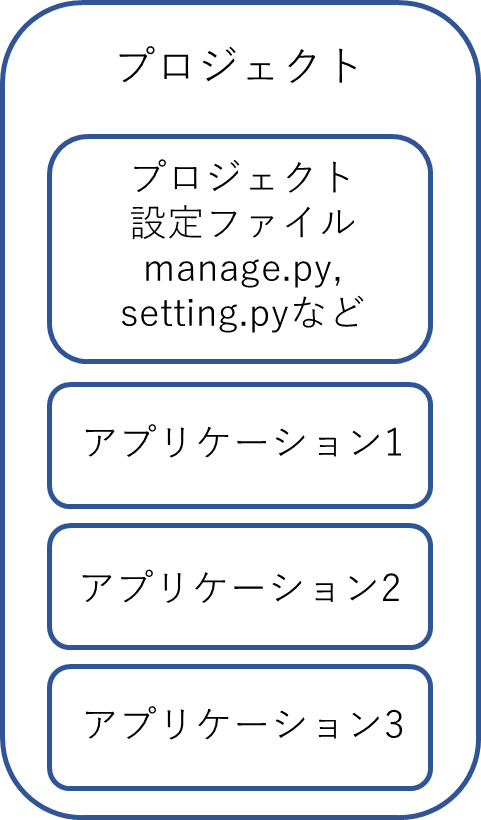
まず、プロジェクトがあり、その中に一つ以上のアプリケーションが存在します。
自動生成されるファイルの構成と説明
ここでは作成して自動生成されたファイルの説明を行う。この他にも手動で生成しなければならないファイルもある。
まず、最上位のプロジェクト名直下にあるmanage.pyを、その後、プロジェクト名の中のもの、最後にアプリケーション名の中のものの順に説明していく。
manage.py
簡単に言うと、コマンドを稼働するためのファイル。色々なコマンドがあるが、代表的なものはサーバーを起動させるrun serverやアプリケーションの作成時に使用したstartappが挙げられる。
asgi.py
デプロイするときに使用するファイル
setting.py
プロジェクト設定ファイル。様々な設定をこのファイルで行う。
urls.py
プロジェクトのルーティングを行うファイル。ブラウザから受け取ったリクエストをもとに、views.pyに命令を出す役割をもっている。ファイル内にあるurlpatternsの名前を見ていき、path関数の第一引数とurlが一致するかを見ていく。一致すれば第二引数の処理をするといったことをするためのファイル
admin.py
管理サイトを設定するためのファイル
apps.py
アプリケーションの構成をどのようにするかを設定するためのファイル
models.py
モデルを定義するためのファイル。データベースを取り扱う際に使用する。
tests.py
テストをするためのファイル
おわりに
今回はdjangoのインストールからプロジェクトとアプリケーションの作成を行いました。次回は作成したものを使い、簡単な実践をします。
はじめてのGithub
準備
自分のGithubのアカウントを登録しておく
GitBashを使えるようにしておく\
はじめに

Git Bashで操作する
それからGithubにのせる用のfizzbuzz.pyをaddする.
git add fizzbuzz.txt
フォルダの中身が複数あり,全てのせたい場合は
git add.
git status
で状態を見てみると,new file: fizzbuzz.pyと表示されるはずだ.
つぎに,先程addしたものをcommitする.
git commit -m "add"
または
git commit -m "[add追加のコメント]
これができれば,自分のGithubとつなげる.
git remote set-url origin コピーしたURL
これで自分のGithubとのせるものが繋がったので,以下を実行.
git push origin master
これで自分の設定したリポジトリに移動すると,以下のようにfizzbuzz.pyがpushできている.

まとめ
はじめてGithubにプログラムをプッシュしました.
苦手なイメージがあって触っていなかったけれど.何か自分の作ったプログラムをのせないと,何もやってないやつ扱いになるのはキツイので頑張ろう..
これはあくまで入門なので,プッシュしてみるだけの内容でした.
5章
デプロイ
まずはデプロイから.
以下よりダウンロードしたディレクトリ内で行う.
git clone https://github.com/tomomano/learn-aws-by-coding-source-code.git
次に作業を行うディレクトリに移動し,ライブラリのインストールから行う.
cd learn-aws-by-coding-source-code/handson/mnist python3 -m venv .env source .env/bin/activate pip install -r requirement.txt
そして,SSH鍵を作り,デプロイを行う.
export KEY_NAME="HirakeGoma"
aws ec2 create-key-pair --key-name ${KEY_NAME} --query 'KeyMaterial' --output text > ${KEY_NAME}.pem
mv HirakeGoma.pem ~/.ssh/
chmod 400 ~/.ssh/HirakeGoma.pem
cdk deploy -c key_name="HirakeGoma"
このときはじめはデプロイできないはずだ.
表示されているURLに飛び,g4dn.xlargeを選択する.つまり,GインスタンスのvCPUの数を4つに申請する.反映されるまで,申請から3日ほどかかる.
改めて,デプロイができると以下が表示される.このIPアドレスを使い,SSHでログインする.

SSHでログイン
生成したHirakeGoma,pemを使い,ログインを行う.
ssh -i ~/.ssh/HirakeGoma.pem -L localhost:8931:localhost:8888 ec2-user@IPアドレス
ここで,-L localhost:8931:localhost:8888について説明する.
これは,自分のローカルマシンのlocalhost:8931へのアクセスをリモートサーバーのlocalhost:8888のアドレスにに転送するという意味である.
これを実行すると,以下の出力がされる.
ssh: connect to host IPアドレス port 22: Connect refused
SSHでやり取りをするポート22への接続が拒否されたようだ.
原因は,SSH接続を受け入れていない,ファイヤーウォールで弾かれている,IPアドレスで認証がおかしいなど考えられる.
このログが出た場合は,SSHの設定を調べて色々してみても,何をしてもだめだったので諦めるしかない.
13章 - DynamoDB (後半)
前回の続き↓から行う.
urhayataro.hatenablog.com
データベースから特定の要素の取り出し
ここではデータベース上で条件を指定し,その条件にあったデータの取り出しをおこなう.
ディレクトリにあるdata.jsonを利用してBatch writeにより複数のデータを一度に書き込む.
import json
with open("data.json", "r") as f:
data = json.load(f)
with table.batch_writer() as batch:
for d in data:
batch.put_item(Item=d)
続いてデータの検索を行う.データの検索にはScanとQueryがある.
まず,Scanについて,これはデータベースの全てのデータを見て,対象のデータを検索する.
使い時は,partition keyやGlobal secondary indexが無いときに使用する.
次に,Queryについて,これは対象となるpartition keyを探し,データを検索する.
Scanと違い,全てのデータは見ないため,partition keyがあればこちらのほうが効率的と言える.
Queryによるデータの検索
では,partition keyを使ってQueryを実行する.
from boto3.dynamodb.conditions import Key, Attr
resp = table.query(
KeyConditionExpression=Key('username').eq('namihei_isono')
)
pprint(resp.get("Items"))これは,KeyConditionExpressionに検索の条件を渡し,partition keyであるusernameがnamihei_isonoの値を検索している.
実行結果は以下のようになる.

次に,上の実行結果のdoseについて見てほしい.namihei_isonoで検索したため,2回ワクチンを受けたなら2回分出力されている.
では,1回目のみ表示したい場合はどうすればいいか.これは&をつける(論理積をとる)ことで条件を追加できる.また,|をつける(論理和をとる)こともできる.
usernameがnamihei_isonoで,doseが1の場合を検索するようにしたのが以下のもの.
resp = table.query(
KeyConditionExpression=Key("username").eq("namihei_isono") & Key('dose').eq(1)
)
pprint(resp.get("Items"))出力結果は次のようになり,1回目のみ出力されている.

では,ageの属性を使ってQueryを実行する.これも先程と同様にKeyConditionExpressionでkeyでどの要素かを指定し,eqでどの値かを検索する.
今回は11歳のデータを検索する.
resp = table.query(
IndexName="ItemsByAge",
KeyConditionExpression=Key('age').eq(11),
)
pprint(resp.get("Items"))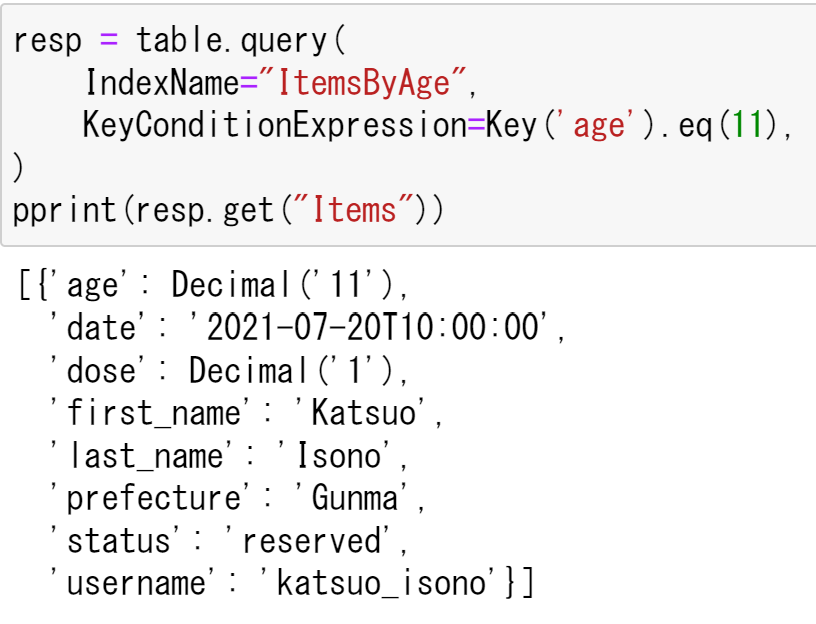
同様にprefectureがTokyoのデータを検索する.
resp = table.query(
IndexName="ItemsByPrefecture",
KeyConditionExpression=Key('prefecture').eq("Tokyo"),
)
pprint(resp.get("Items"))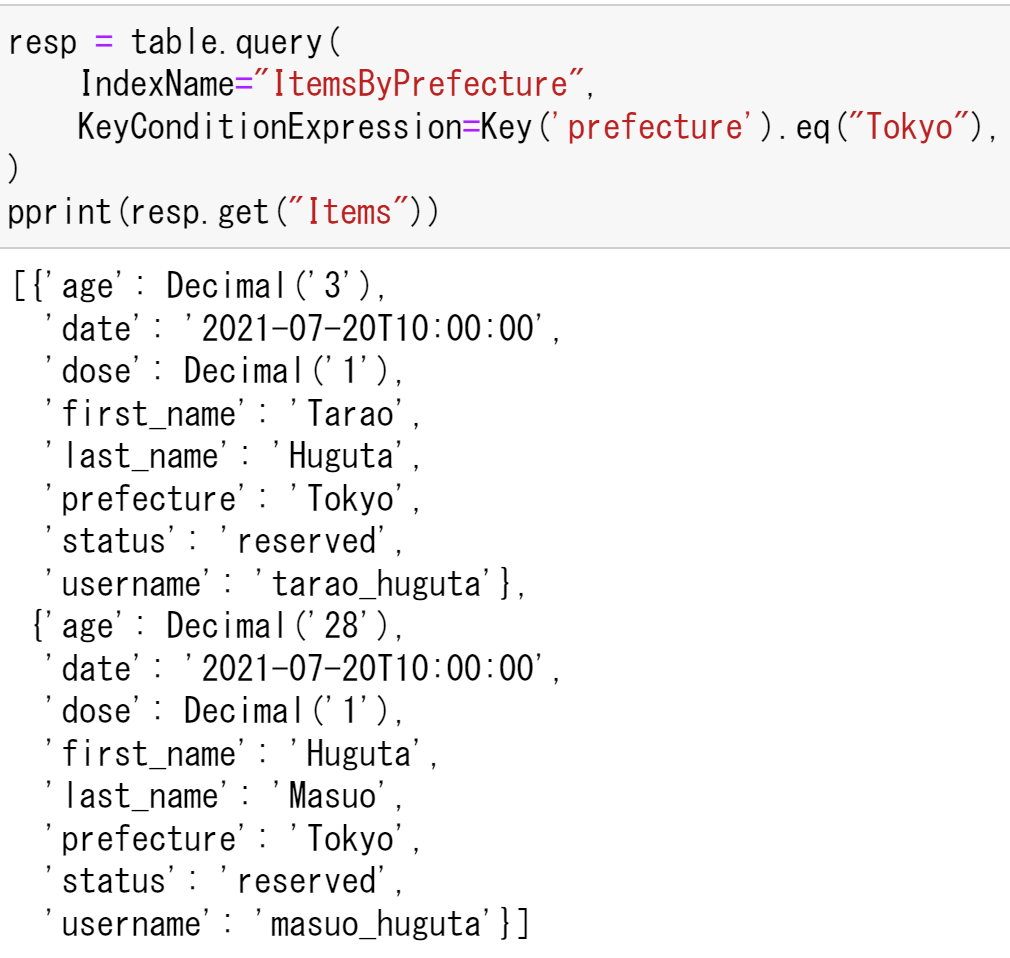
ここまでで,Queryは以下のようにすると使えることがわかった.
resp = table.query(
IndexName="ItemsByPrefecture",
KeyConditionExpression=Key('検索する属性').eq("検索する内容"),
)
pprint(resp.get("Items"))
Scanによるデータの検索
全てのデータを検索
はじめに,条件を指定せず全てのデータベースの要素を取ってくる.
resp = table.scan()
items = resp.get("Items")
print("Number of items", len(items))すると以下の出力が得られる.

ただ,ScanもQueryも1MB以上の範囲を検索できない.それ以上検索したければ,前回検索した続きから検索を続ける必要がある.以下のようにすれば良い.
resp = table.scan()
items = resp.get("Items")
while resp.get("LastEvaluatedKey"):
resp = table.scan(EsclusiveStartKey=r[:"LastEvalutedKey"])
items.extend(resp["Items"])
print("Number of items", len(items))Scan()から返されるディクショナリにLastEvakutedKeyがある.これが空ならデータベース内が全てScanし終えたことを意味する.
Scan()を続きから実行する場合には,ExclusiveStartKeyに前回呼んだ最後のprimary keyを渡す.このコードでは,LastEvakutedKeyが空になるまでScan()を繰り返すようにしている.
実行結果は以下のようになった.

条件をつけて検索
Scanの場合は,Filter Expressionに特定の条件を記述する方法で検索することができる.
例として,ageが27以下の要素を検索する.
resp = table.scan(
FilterExpression=Attr('age').lt(27)
)
print("Number of items", len(resp.get("Items")))
同様に,dateが2021-07-25の要素を検索する.
resp = table.scan(
FilterExpression=Attr('date').begins_with("2021-07-25"),
)
pprint(resp.get("Items"))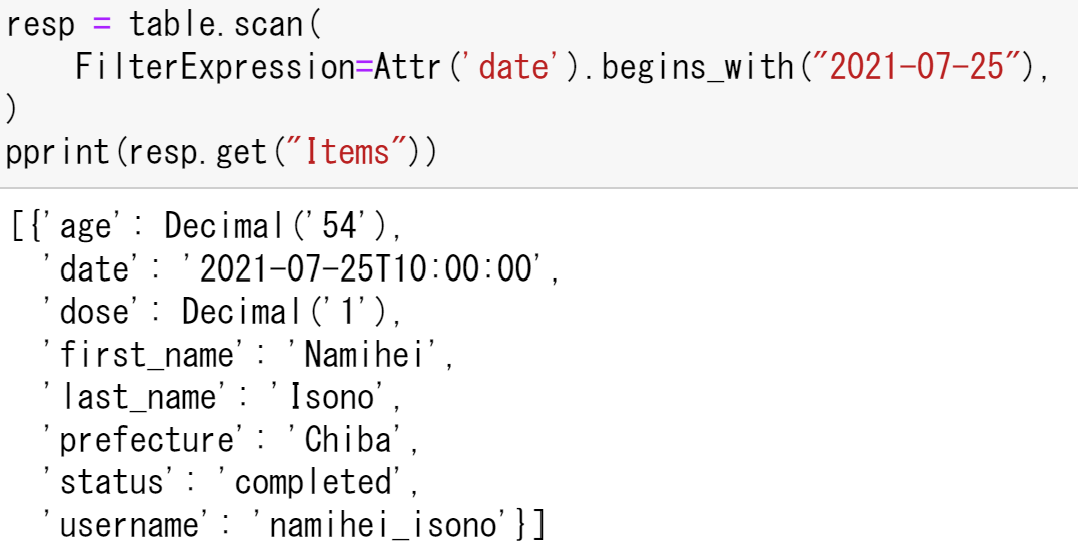
これで,2行目のFilterExpression=以下で条件を定めれば,検索をかけられることがわかった.
Scanで検索するときに一部の属性を取り出すという便利な検索の方法がある.
その方法は,ProjectExpressionを使用することで,指定した属性のみを表示することができる.
今までは,条件に合ったデータを持ったもののデータを全て表示していたが,例えば,first_nameとprefectureのみを取り出すこともできる.
resp = table.scan(
ProjectionExpression="first_name, prefecture"
)
print(resp.get("Items"))
これで名前と住所のみ取り出せていることがわかる.
バックアップを取る
バックアップの流れ
データベースを扱うときに必須であるバックアップの取り方について触れていく.
流れとしては,バックアップを取り,データベースを書き換え,復元する.元のデータベースになっていれば成功という感じだ.
バックアップの取得
バックアップはTable()ではサポートされていなので,client()を使って行う.
まず,DynamoDBのclient()オブジェクトを作る.
client = session.client("dynamodb")次に,バックアップを取るためのcreate_backup()を使って書いていく.これにバックアップを取るテーブル名と,バックアップの名前を指定する必要がある.これが2,3行目に該当する.また,BackupArnは,バックアップのIDとなっている.
resp = client.create_backup(
TableName=table_name,
BackupName=table_name + "-Backup"
)
backup_arn = resp["BackupDetails"]["BackupArn"]
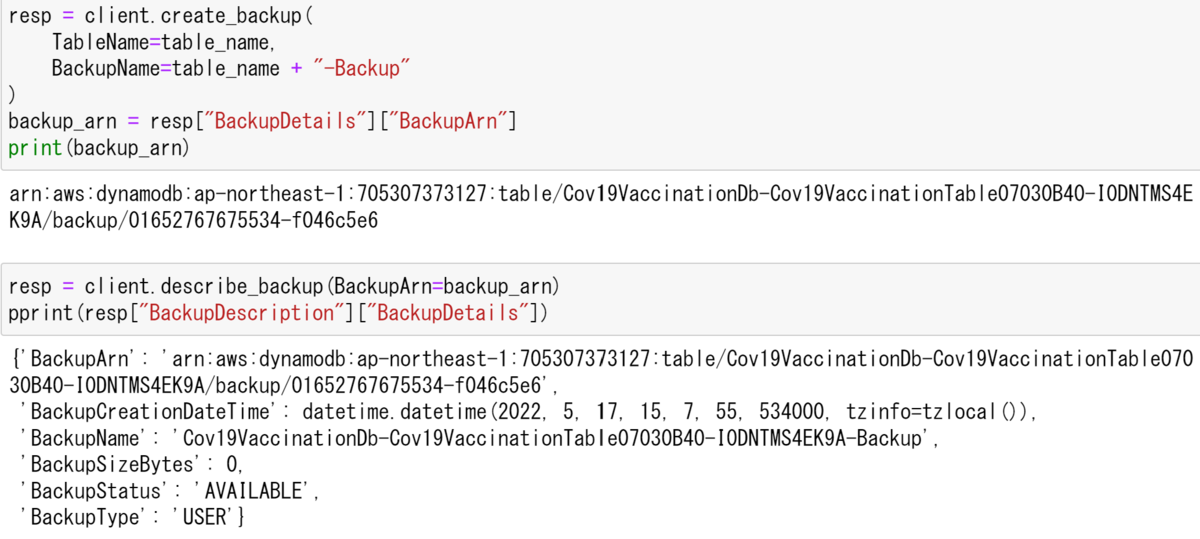
print(backup_arn)続いてバックアップの情報を取得する.
resp = client.describe_backup(BackupArn=backup_arn) pprint(resp["BackupDescription"]["BackupDetails"])
以下のような出力が表示されるはずだ.
ここまでできれば,AWSの方でバックアップが取れているか確認する.
AWSからDynamoDB→テーブル→テーブル名→バックアップを確認する.
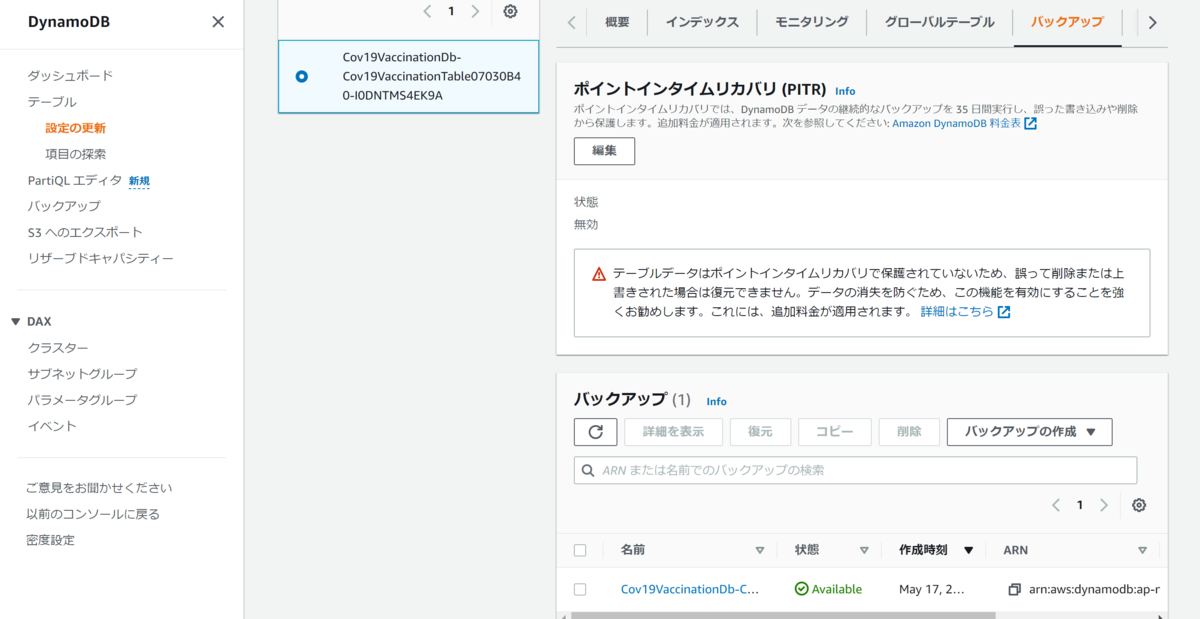
バックアップが1つあり,状態がAvailableとなっている.
これでバックアップが作成できたことがわかった.
データベースの書き換えと復元
まず,元のデータベースを書き換えてみる.書き換えるのは何でも良い.
前半のデータベースの更新を参考に書き換えていく.
urhayataro.hatenablog.com
resp = table.update_item(
Key={"username": "tarao_huguta", "dose": 1},
UpdateExpression="SET age = :val1",
ExpressionAttributeValues={
":val1": 4
}
)
resp = table.get_item(
Key={"username": "tarao_huguta", "dose": 1},
)
pprint(resp["Item"]["age"])すると値が書き換えられた.

書き換えが終われば復元してみる.
restored_table_name = table_name + "-restored"
resp = client.restore_table_from_backup(
TargetTableName=restored_table_name,
BackupArn=backup_arn,
)2行目の.restore_table_from_backup()でバックアップの復元を行っている.
また,1行目で復元後のテーブルの名前を指定し,3行目に渡している.
続いて,復元したテーブルの状態を確認する.確認は以下のように行う.
resp = client.describe_table(TableName=table_name + "-restored") pprint(resp["Table"]["TableStatus"])
describe_table()でテーブル名を指定し,そのテーブルの状態を表示させている.

復元直後はCREATINGとなり,しばらくするとACTIVATEになる.ACTIVATEにならないとデータベースの読み書きができない点に注意する.
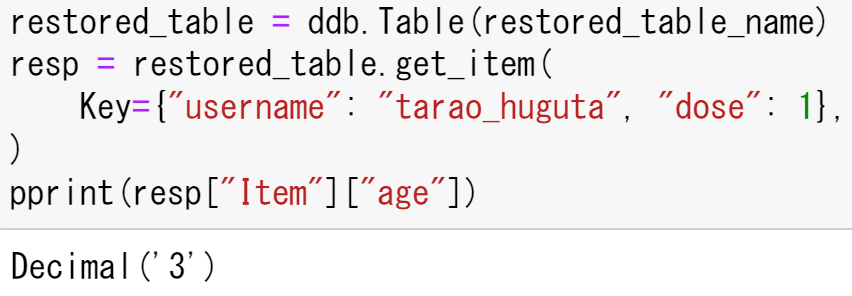
復元が終われば,書き換えたところをもう一度読み取り,復元できているかの確認を行う.
restored_table = ddb.Table(restored_table_name)
resp = restored_table.get_item(
Key={"username": "tarao_huguta", "dose": 1},
)
pprint(resp["Item"]["age"])出力は以下のようになり,4と書き換えたのが,3に復元できていることから,バックアップでの復元ができていることがわかる.
これでデータベースのバックアップ及び復元を終える.
最後に復元されたテーブルと,不要なバックアップのデータを削除しておく.
restored_table.delete() resp = client.delete_backup(BackupArn=backup_arn)
それからスタックも削除しておく
cdk destroy
まとめ
13章後半ではデータベースについて扱った.
データの読み書きバックアップと復元について触れ,データの更新のやり方や条件に該当するデータの読み取りについても行った.
バックアップについて,よく行う作業だとは思うのでcreate_backup()での作成は大切になる.
以上で13章DynamoDBを終える.